
2025 年 7 月 9 日讯,在生命科学探索的漫漫长路上,基因组一直是一座神秘而巍峨的高山,横亘在人类对自身奥秘认知的前方。浙江大学郭国骥教授团队宛如无畏的攀登者,成功开发出多任务深度学习模型女娲 CE(NvwaCE),实现从基因组序列到单细胞水平调控序列图谱的直接预测,一举攻克基因组 AI 领域的关键难题,其成果荣登《细胞》杂志,在全球科学界激起千层浪。
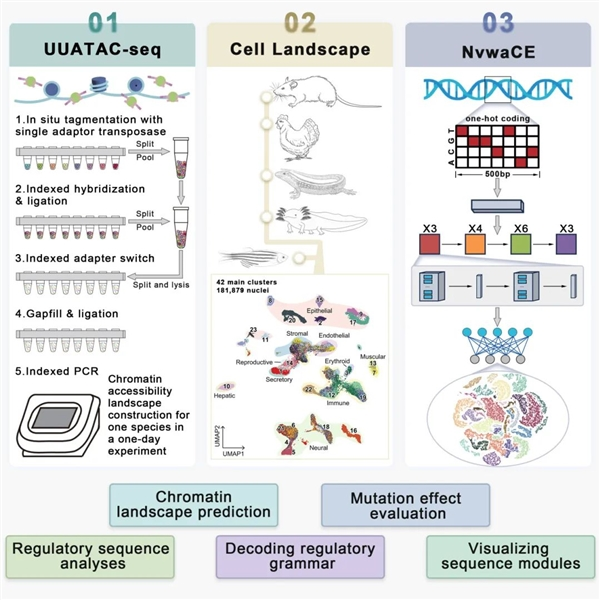
基因组,这座由 DNA 构成的 “生命蓝图”,不仅包含编码蛋白质的序列,更蕴藏着海量的调控序列,它们交织在一起,共同谱写着生物体复杂特征的 “生命乐章”。自 2003 年人类基因组计划大功告成,成功绘制出基因图谱,如同为这座神秘的高山勾勒出大致轮廓,然而,对其中遗传信息的解读却仅如沧海一粟,不足 10%。长久以来,科学家们在这片未知领域艰难摸索,试图找到开启遗传密码宝库的钥匙。
AI 技术的横空出世,宛如一道曙光,为解读基因序列带来了全新可能。但基因组 AI 模型的发展并非一帆风顺,数据质量成为制约其前行的 “拦路虎”。在此关键时刻,郭国骥团队挺身而出,凭借自主研发的超高通量超灵敏单核 ATAC 测序技术(UUATAC-seq),为基因组 AI 模型训练精心打造了一套高质量 “教材”。该技术创新性地采用单末端转座酶与温控接头转换策略,在实验效率、通量、灵敏度和特异性上全面超越同类技术,甚至能够在单日内高效率高质量地完成一个物种的染色质可及性图谱绘制,为后续研究奠定了坚实基础。
依托 UUATAC-seq 产出的高质量数据,女娲 CE 模型宛如一位勤奋的 “学生”,迅速掌握了脊椎动物调控序列的编码规则。如今,它已具备强大能力,能够基于一维 DNA 序列,精准预测单细胞中的染色质可及性水平。更为惊艳的是,该模型拥有极高的泛化能力,面对未经训练的物种,也能从容预测其染色质可及性图谱,并且对人类调控元件可及性的预测结果与实验测量数据高度吻合,展现出卓越的可靠性。
步入实际应用领域,女娲 CE 模型更是 “大显神通”,将现有基因组 AI 模型远远甩在身后。它能够精准预测合成突变对谱系特异性调控序列功能的影响,为科研人员解析基因功能、探究遗传疾病发病机制提供了有力工具;同时,还能紧密结合疾病表型,巧妙设计治疗位点,开启了精准医疗的全新篇章。
在镰刀型贫血症的治疗研究中,团队基于女娲 CE 模型预测出治疗性基因位点 HBG1-68:A>G,并通过基因编辑实验加以验证。结果令人振奋,经基因治疗后,胎儿血红蛋白表达量显著提升,成功攻克这一困扰医学界多年的难题。这一成果堪称世界首例由人工智能设计的人类疾病治疗位点,彰显了女娲 CE 模型在医学领域的巨大应用潜力。
与国外同类模型相比,女娲 CE 模型优势尽显。它扎根于高质量单细胞图谱数据,对几乎所有细胞类型都实现了 AUROC>0.90 的预测准确率,如此高的精度让其他模型望尘莫及。
展望未来,女娲 CE 模型恰似一把万能钥匙,将在生命科学、医学和农学等诸多领域大施拳脚。它有望助力科学家全面解读基因组语言,构建起更为完善的数字生命模型,为人类健康、农业发展等带来革命性突破。随着研究的持续深入,相信女娲 CE 模型将不断释放潜能,引领人类在探索生命奥秘的征程上大步迈进,创造更多生命科学领域的奇迹。